What is Retrieval Augmented Generation (RAG)? Business Implementation Guide
Learn how RAG combines large language models with your proprietary data to create accurate, business-specific AI applications. Complete implementation guide with real-world examples.

Eric Garza
Large language models like ChatGPT are impressive, but they have critical limitations for business use: they're trained on general internet data, they don't know your business specifics, and they can hallucinate incorrect information.
Retrieval Augmented Generation (RAG) solves these problems by connecting LLMs to your proprietary business data, enabling AI that's both powerful and accurate for your specific domain.
This guide explains RAG in plain English, shows real business applications, and provides a practical implementation roadmap.
What is Retrieval Augmented Generation (RAG)?
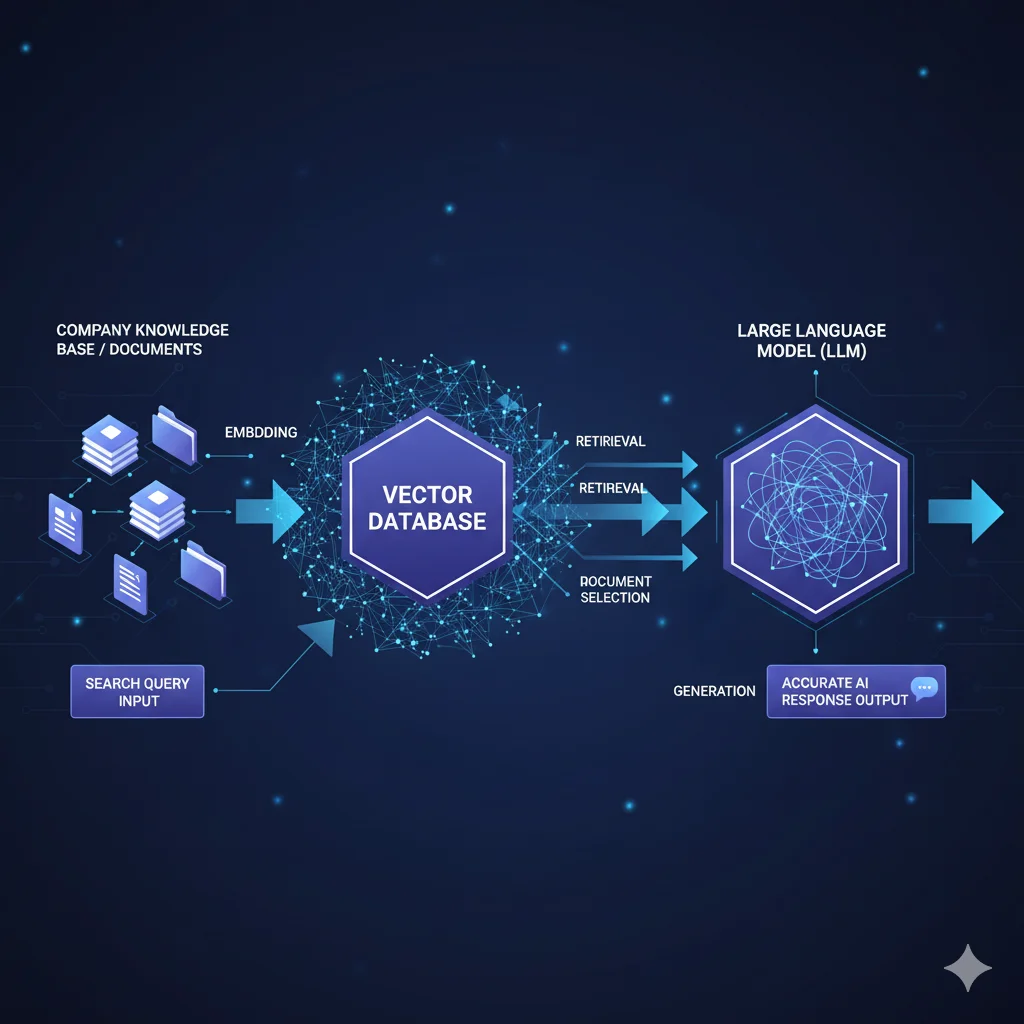
RAG is a technique that enhances large language models by retrieving relevant information from your own knowledge base before generating responses.
Think of it like this:
- Traditional LLM: Answers based only on what it learned during training (generic, possibly outdated)
- RAG-enhanced LLM: First searches your company documents, then generates answers using that specific, current information
Simple Example:
Question: "What is our refund policy for enterprise customers?"
Without RAG (Generic LLM): "Most companies offer 30-day refund policies, but specific terms vary..." (Generic, possibly wrong for your business)
With RAG (Your Business Data): Searches your internal policy documents → Finds relevant section → Generates accurate response: "According to your enterprise policy document updated Jan 2025, enterprise customers have a 60-day money-back guarantee with no questions asked..."
How RAG Works: The Technical Flow
Step 1: Index Your Knowledge Base
Your business knowledge sources:
- Product documentation
- Support tickets and FAQs
- Internal wikis and knowledge bases
- Contracts and legal documents
- Training materials
- Customer data (with privacy controls)
Indexing process:
- Break documents into chunks: Split large docs into searchable segments
- Create embeddings: Convert text to numerical vectors capturing meaning
- Store in vector database: Specialized database for similarity search
Example: Your 500-page employee handbook is split into 2,000 searchable chunks, each converted to a 1,536-dimension vector.
Step 2: Query Processing
When user asks a question:
- Convert question to same embedding format
- Search vector database for most similar content
- Retrieve top 3-10 most relevant chunks
Example: User question: "How many vacation days do employees get?" → System retrieves handbook sections on PTO policy, accrual rates, and carryover rules
Step 3: Augmented Generation
LLM receives:
- User's original question
- Retrieved relevant context from your documents
- Instruction to answer based on provided context
Output: Accurate, source-grounded answer specific to your business
Learn about our LLM integration services
RAG vs. Other LLM Approaches
| Approach | How it Works | Accuracy | Cost | Use Cases |
|---|---|---|---|---|
| Generic LLM | Pre-trained model only | 60-70% for business specifics | Low ($0.01-0.03 per query) | General knowledge, creative writing |
| Fine-Tuning | Retrain model on your data | 80-90% | High ($10K-$100K+, ongoing) | Specialized language, domain expertise |
| RAG | LLM + your data retrieval | 85-95% | Moderate ($0.05-0.15 per query) | Q&A, customer support, research |
| RAG + Fine-Tuning | Both techniques combined | 90-98% | Very High | Mission-critical, specialized domains |
Why RAG is often best for business:
- Much cheaper than fine-tuning ($50K-$200K saved)
- Continuously updated (add new docs without retraining)
- More transparent (you see which sources were used)
- Faster to implement (weeks vs. months)
Real-World Business Applications
Application 1: Customer Support Automation
Problem: Support agents spend 40% of time searching knowledge base
RAG Solution:
- Index all product docs, support tickets, troubleshooting guides
- AI assistant searches relevant content for each customer query
- Provides accurate answer with source citations
- Escalates only when uncertain
Results:
- 60% of customer queries handled autonomously
- 80% faster response time for complex issues
- Customer satisfaction up 25%
Explore our customer support AI solutions
Application 2: Contract Analysis
Problem: Lawyers spend 15 hours reviewing each M&A contract
RAG Solution:
- Index standard clauses, precedent agreements, regulatory requirements
- AI extracts key terms, identifies risks, flags deviations
- Compares against company standards and regulatory guidelines
- Generates summary and recommendations
Results:
- Contract review time reduced to 3 hours
- 95% accuracy in risk identification
- Consistent application of company standards
Application 3: Sales Enablement
Problem: Sales reps struggle to find product info during customer calls
RAG Solution:
- Index product specs, competitive analyses, case studies, pricing
- During customer call, AI suggests relevant talking points
- Answers product questions with current, accurate information
- Provides competitive differentiators automatically
Results:
- 40% reduction in deal cycle time
- 30% increase in win rate
- New rep ramp time reduced 50%
Discover our sales AI capabilities
Application 4: Employee Onboarding Assistant
Problem: HR team answers same onboarding questions repeatedly
RAG Solution:
- Index employee handbook, benefits guides, IT procedures, facilities info
- New hires ask questions in natural language
- AI provides accurate, up-to-date answers with policy citations
- Escalates only unique or sensitive questions
Results:
- 75% reduction in HR time on routine questions
- Better new hire experience (instant answers)
- Consistent policy communication
Implementation Guide: Building Your RAG System
Phase 1: Planning (Weeks 1-2)
Step 1: Define Use Case
- Identify high-value knowledge domain
- Quantify current pain points
- Define success metrics
Example Metrics:
- Time savings (hours saved per week)
- Accuracy improvement (% correct answers)
- User satisfaction (NPS or CSAT)
Step 2: Inventory Data Sources
- List all relevant knowledge repositories
- Assess data quality and structure
- Identify access/permission requirements
- Plan for data privacy and compliance
Step 3: Choose Architecture
- Cloud vs. on-premise
- Vector database selection (Pinecone, Weaviate, Azure Cognitive Search)
- LLM selection (GPT-4, Claude, Azure OpenAI)
- Integration approach
Phase 2: Development (Weeks 3-8)
Step 1: Data Preparation (Weeks 3-4)
- Extract content from source systems
- Clean and format data
- Remove duplicates and outdated content
- Split documents into optimal chunk sizes
Best Practices:
- Chunk size: 300-500 words typically optimal
- Overlap chunks slightly to preserve context
- Maintain metadata (source, date, author, category)
- Tag with keywords for hybrid search
Step 2: Indexing (Week 5)
- Generate embeddings for all content chunks
- Load into vector database
- Create indexes for fast similarity search
- Test retrieval quality
Embedding Model Options:
- OpenAI
text-embedding-ada-002(general purpose, cost-effective) - Azure OpenAI embeddings (enterprise compliance)
- Open source models (Sentence Transformers for on-premise)
Step 3: RAG Pipeline Development (Weeks 6-7)
- Build query processing logic
- Implement retrieval (with reranking for better results)
- Configure LLM prompt engineering
- Add source attribution and confidence scoring
Prompt Engineering Example:
You are a helpful AI assistant for [Company Name].
Context from our knowledge base:
{retrieved_context}
User question: {user_question}
Instructions:
- Answer based ONLY on the provided context
- If context doesn't contain answer, say "I don't have that information"
- Cite which document you're referencing
- Be concise and accurate
Answer:
Step 4: Testing & Refinement (Week 8)
- Create test question set (50-100 diverse queries)
- Evaluate accuracy against ground truth
- Optimize retrieval parameters
- Refine prompts for better results
Phase 3: Deployment (Weeks 9-12)
Step 1: Pilot with Limited Users (Weeks 9-10)
- Deploy to small user group (10-20 people)
- Collect feedback and usage patterns
- Monitor for errors and hallucinations
- Iterate based on learnings
Step 2: Production Rollout (Weeks 11-12)
- Deploy to full user base
- Provide training and documentation
- Set up monitoring and alerting
- Establish feedback loops for continuous improvement
Step 3: Ongoing Optimization
- Add new content sources
- Retrain embeddings quarterly
- Update prompts based on user feedback
- Expand use cases
Schedule a RAG implementation consultation
Common RAG Challenges and Solutions
Challenge 1: Retrieval Quality
Problem: System retrieves irrelevant or outdated content
Solutions:
- Hybrid search: Combine semantic (vector) and keyword search
- Reranking: Use second model to score and rerank retrieved results
- Metadata filtering: Filter by date, category, department before search
- Query expansion: Rephrase question multiple ways, search all variations
Challenge 2: Chunk Boundaries
Problem: Important context split across multiple chunks
Solutions:
- Overlapping chunks: Include 50-100 word overlap between chunks
- Hierarchical retrieval: Retrieve chunk + surrounding context
- Document-level retrieval for short docs: Don't chunk very short documents
Challenge 3: Hallucination Despite RAG
Problem: LLM still makes up information not in retrieved context
Solutions:
- Strict prompts: Explicitly forbid information not in context
- Confidence scoring: Model outputs confidence, threshold for "don't know"
- Source citation: Require specific document citation for each claim
- Human review: Flag low-confidence answers for verification
Challenge 4: Slow Response Times
Problem: Queries take 10+ seconds (poor user experience)
Solutions:
- Optimize vector search: Use approximate nearest neighbor indexes
- Reduce retrieval size: Retrieve fewer chunks (quality over quantity)
- Streaming responses: Show partial response while generating
- Caching: Cache common queries and their responses
Challenge 5: Data Privacy and Security
Problem: Sensitive data might be exposed inappropriately
Solutions:
- Access control: Filter retrieved content based on user permissions
- Data classification: Tag sensitive content, exclude from certain queries
- Audit logging: Track all queries and responses
- On-premise deployment: Keep data within corporate firewall
Cost Analysis: Building a RAG System
Typical Implementation Costs (Mid-Market Company)
One-Time Implementation:
- Data preparation and cleaning: $30,000-$80,000
- RAG system development: $60,000-$150,000
- Vector database setup: $15,000-$40,000
- Testing and optimization: $20,000-$50,000
- Total Implementation: $125,000-$320,000
Ongoing Annual Costs:
- LLM API usage: $18,000-$90,000/year (varies by query volume)
- Vector database hosting: $12,000-$40,000/year
- Maintenance and updates: $30,000-$80,000/year
- Total Annual Operational: $60,000-$210,000
ROI Example (Customer Support Use Case):
- Implementation: $200,000
- Annual operational: $100,000
- Support time savings: 5,000 hours/year × $50/hour = $250,000/year
- Year 1 ROI: ($250K - $200K - $100K) / $300K = -16.7% (investment year)
- Year 2 ROI: ($250K - $100K) / $100K = 150%
- Payback period: 14 months
Advanced RAG Techniques
Multi-Step Reasoning
Problem: Complex questions require multiple retrieval steps
Solution: Agentic RAG
- Break question into sub-questions
- Retrieve context for each
- Synthesize final answer from multiple sources
Example: "Compare our enterprise vs. professional plan pricing and recommend which is best for a 50-person marketing agency." → Retrieves: Pricing info, feature comparison, typical customer profiles → Synthesizes personalized recommendation
Conversational RAG
Problem: Follow-up questions lack context
Solution: Maintain conversation history
- Store previous queries and responses
- Use conversation context to disambiguate follow-ups
- Retrieve relevant historical context
Example: User: "What is our return policy?" Bot: [Provides answer] User: "What about for damaged items?" → System knows "damaged items" relates to "return policy" from context
Multi-Modal RAG
Problem: Not all knowledge is text (diagrams, charts, images)
Solution: Multi-modal embeddings
- Index images, charts, diagrams alongside text
- Use vision-language models (GPT-4V, Claude 3)
- Retrieve both text and visual content
Example: "Show me the network architecture diagram" → Returns relevant diagram with explanation
Conclusion: RAG as Enterprise AI Foundation
RAG represents the practical path to deploying LLMs in business contexts. It bridges the gap between powerful general-purpose AI and your specific business needs.
Key Takeaways:
- RAG combines LLM power with your business knowledge for accurate, domain-specific AI
- More cost-effective than fine-tuning (65-80% savings) with comparable accuracy
- Continuously updatable-add new documents without retraining
- Wide business applications-customer support, sales, HR, legal, research
- Implementation timeline: 8-12 weeks to production for typical use case
Best starting use cases:
- Internal knowledge Q&A (employees asking about policies, procedures)
- Customer support automation (product questions, troubleshooting)
- Sales enablement (product info during customer conversations)
ROI expectations:
- 40-70% time savings on knowledge-intensive tasks
- 85-95% accuracy for domain questions
- 10-18 month payback period
- Ongoing value as knowledge base grows
Ready to build a RAG system for your business knowledge? Schedule a strategy session with our AI integration experts. We'll assess your use case, estimate ROI, and create a phased implementation roadmap using Azure OpenAI for enterprise-grade security and compliance.
About AI Conexio: We specialize in RAG implementations using Azure OpenAI Service, ensuring your proprietary data remains secure while leveraging state-of-the-art language models. Our proven RAG methodology delivers production systems in 8-12 weeks with guaranteed accuracy thresholds.
Was this article helpful?
About Eric Garza
With a distinguished career spanning over 30 years in technology consulting, Eric Garza is a senior AI strategist at AIConexio. They specialize in helping businesses implement practical AI solutions that drive measurable results.
Eric Garza has a proven track record of success in delivering innovative solutions that enhance operational efficiency and drive growth.


